©Richard Lowry, 1999-
All rights reserved.
Chapter 15.
One-Way Analysis of Variance for Correlated Samples
Part 3
¶Assumptions of the One-Way ANOVA for Correlated Samples
The first four of these assumptions are the same as for the independent-samples ANOVA:
- that the scale on which the dependent variable is measured has the properties of an equal interval scale;
- that the measures within each of the k groups are independent of each other (as indicated in Chapter 14, the independent-samples ANOVA also assumes that the measures are independent [non-correlated] across the groups);
- that the source population(s) from which the k samples of measures are drawn can be reasonably supposed to have a normal distribution; and
- that the k groups of measures have approximately equal variances.
As noted in Chapter 14, the analysis of variance is quite robust with respect to assumptions 3 and 4, providing that the k groups are all of the same size. In the correlated-samples ANOVA this provision is always satisfied, since the number of observations within each of the k groups of measures is necessarily equal to the number of subjects in the repeated measures design, or to the number of matched sets of subjects in the randomized blocks design.
Figure 15.3 shows these intercorrelations for the
Figure 15.3. Intercorrelations among Groups A, B, and C
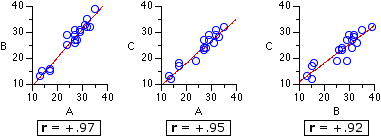
Note incidentally that the degree of intercorrelation among the k groups of measures is directly related to SSsubj, which is the aggregate measure of individual differences among the subjects in a repeated measures design, or among the matched sets of subjects in a randomized blocks design. The greater the degree of intercorrelation, the greater will be the size of SSsubj. |
¶Post-ANOVA Comparisons: the Tukey HSD Test
In the independent-samples version of ANOVA, the "error term" of the
For the example considered in the present chapter, recallTthat |
Here again is the calculator for critical values of Q for the .05 and .01 levels of significance. It is exactly the same calculator that appeared in Chapter 14, except now the entry for df is subscripted as dferror. Recall that values of K must fall between 3 and 10, inclusive.
| k | dfwg | Q.05 | Q.01 |
Entering k=3 and
| HSD.05 | = | Q.05 x sqrt | [ |
MSerror Nsubj | ] | That is: In order to be considered significant at or beyond the .05 level, the difference between any two particular group means (larger—smaller) must be equal to or greater than 1.42.
|
|
| = | 3.47 x sqrt | [ | 3.0 | 18 ] |
|
|
| = | 1.42 | |
and for the .01 level:
| HSD.01 | = | Q.01 x sqrt | [ |
MSerror Nsubj | ] | That is: In order to be considered significant at or beyond the .01 level, the difference between any two particular group means (larger—smaller) must be equal to or greater than 1.8.
|
|
| = | 4.42 x sqrt | [ | 3.0 | 18 ] |
|
|
| = | 1.8 | |
The blue entries in the following table show the differences
| A·B | Ma=25.9 Mb=26.9 | 1.0 |
HSD.05 = 1.42 HSD.01 = 1.8 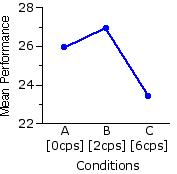
| A·C
| Ma=25.9 | Mc=23.4 2.5 |
| B·C
| Mb=26.9 | Mc=23.4 3.5 | |
Our investigator would therefore be able to conclude that performance on the rotary pursuit task is better under the 0cps and 2cps condition than it is under the 6cps condition. Notwithstanding the fact that Mb is greater than Ma, she would not be able to conclude that performance is better under the 2cps condition than under the 0cps condition.
¶Step-by-Step Computational Procedure: One-Way Analysis of Variance for Correlated Samples
Here again I will show the procedures for one particular value of k,
Step 1. Combining all k groups of measures together, calculate
| SST = ∑X2i — | (∑Xi)2 NT |
Step 2. For each of the k groups separately, calculate the sum of squared deviates within the
| SSg = ∑X2gi — | (∑Xgi)2 Ng |
Step 3. Take the sum of the SSg values across all k groups to get
| SSwg = SSa+SSb+SSc |
Step 4. Calculate SSbg as
| SSbg = SST—SSwg |
Step 4a. Check your calculations up to this point by calculating SSbg separately as
| SSbg | = | (∑Xai)2 Na | + | (∑Xbi)2 Nb | + | (∑Xci)2 Nc | — | (∑XT)2 NT |
Step 5. Calculate SSsubj as
| SSsubj | = | k | — | (∑XTi)2 NT |
Step 6. Calculate SSerror as
| SSerror = SSwg — SSsubj |
Step 7. Calculate the relevant degrees of freedom as
dfT = NT—1dfbg = k—1dfwg = NT—k|
| dfsubj = Nsubj—1dferror = dfwg—dfsubj |
Step 8. Calculate the relevant mean-square values as
| MSbg | = | SSbg dfbg and |
| MSerror | = | SSerror | dferror | ||
Step 9. Calculate F as
| F | = | MSbg MSerror |
Step 10. Refer the calculated value of F to the table of critical values of F (Appendix D), with the appropriate pair of numerator/denominator degrees of freedom, as described earlier in this chapter.
Note that this chapter includes a subchapter on the Friedman Test, which is a non-parametric alternative to the one-way ANOVA for correlated samples.
End of Chapter 15, Part 2.
Return to Top of Chapter 15, Part 3
Go to Subchapter 15a [The Friedman Test]
Go to Chapter 16 [Two-Way Analysis of Variance for Independent Samples]
| Home | Click this link only if the present page does not appear in a frameset headed by the logo Concepts and Applications of Inferential Statistics |