©Richard Lowry, 1999-
All rights reserved.
Chapter 9.
Introduction to Procedures Involving Sample Means
Part 2
Oh, the joys of creation, especially when it can be done fairly simply with a few lines of programming code. Once again, somewhere deep within the electronic workings of your computer I have created a vast population of Xi values. This time, however, all I will tell you about the population is that it is normally distributed. The rest of its main properties—mean, variance, and standard deviation—you will have to figure out for yourself, starting from scratch. Note, incidentally, that this scenario is much closer to reality than the one described in Part 1 of this chapter. There are many real-life research situations where we can reasonably suppose that a source population is normally distributed, but rarely if ever do we know in advance the true values of its central tendency and variability. We will begin with the easiest part of the task, which is to figure out the mean of the population.
¶Estimating the Mean of a Normally Distributed Source Population
In Part 1 we noted that a random sample will tend to reflect the properties of the population from which it is drawn. Among these reflected properties is the population's central tendency. So here is the simple, straightforward way of estimating the mean of our current source population. Draw from it a random sample of size N, and then let the mean of that sample serve as your estimate of the mean of the population.
The principle underlying such a process is that the mean of any particular sample can be taken as an unbiased estimate of the mean of the population from which the sample is drawn. In general, a biased estimate is one that will systematically underestimate the true value, or systematically overestimate it, while an unbiased estimate is one that avoids this tendency. The unbiased estimate might prove to be either under or over the true value in particular cases, but it will not move in either of these directions systematically. It is roughly analogous to shooting arrows at a target. The archer who tends to hit below the bull's eye is systematically biased in one direction, while the archer who tends to hit above it is systematically biased in the other. An archer without such a systematic bias will hit below and above the bull's eye in equal measure, and occasionally she will even hit it dead center.
But of course, even an unbiased archer is not necessarily a contender for the world title. The shots of one might tend to cluster within two or three inches of dead center, while those of another might scatter out over a distance of two or three feet. Similarly, some sample means can be regarded as very close estimates of the population mean, while others can be taken only as loose ballpark estimates.
In the following table is a button labeled "Sample." Each time you click it, you computer will draw a random sample of whatever size is indicated in the cell labeled "sample size." The default value of "sample size" is 5, though you can reset it to any positive integer value you might wish. I suggest you begin by drawing a few samples of size N=5, then a few of size N=10, and so on until you have worked your way up to some fairly large sample sizes. By the time you are drawing samples of size N=100, you will begin to get a pretty close fix on the mean of the source population. With samples of larger sizes, it will be closer still. (Note, however, that large sample sizes will take longer to run, especially if your browser is Internet Explorer. ) To help you avoid getting lost in the fractional numerical details of your samples, each sample mean is also shown rounded to the nearest integer value.
So, click, click, click away. And then, when you have finished, click here to continue with the text of this chapter.
If you have taken the time to perform the above exercise, you have almost certainly arrived at the conclusion that the mean of our current source population is somewhere in the vicinity of 15. Perhaps a shade more than 15, perhaps a shade less, but in any event somewhere in that vicinity.
Just how narrowly or broadly you can set the boundaries of "vicinity" depends on the size of the sample. The fact that the mean of our current source population lies somewhere in the neighborhood of 15 might not have been very obvious when you were drawing small samples, but it must surely have become so as the sizes of your samples increased. In general, a larger sample sets the boundaries of "vicinity" more narrowly, while a smaller sample sets them more broadly. From what we observed in Part 1 concerning the sampling distribution of sample means, you will know that these boundaries are also determined by the amount of variability that exists within the population from which the sample is drawn. A relatively small amount of variability within the source population would define "vicinity" fairly narrowly, while a relatively large amount would define it fairly broadly. Either way, the general structure of this process of estimation is
estimated 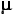 source = MX±[definition of "vicinity"]
source = MX±[definition of "vicinity"]
In Chapter 10 we will show precisely how you go about defining the boundaries of "vicinity." Meanwhile, so as not to keep you in suspense, I will tell you that your estimate of "somewhere in the vicinity of 15" is right on target. The mean of the source population from which you were drawing your samples is precisely
source = 15.0
¶Estimating the Variability of a Normally Distributed Source Population
The principle here is akin to the one just discussed in connection with the central tendencies of samples and populations, though with one very important difference. The variability that is observed to exist within a sample can be taken as an estimate of the variability of the population, but not as an unbiased estimate. In general, the variability that appears within samples will tend to be smaller than the variability that exists within the entire population. In a relatively small percentage of cases it will be larger, and occasionally it might even hit the variability of the population dead center; but overall there is a strong bias in favor of the observed variability of a sample coming out as an underestimate of the variability of the population.
Here as well, the basic concept is that a random sample will tend to reflect the properties of the population from which it is drawn. Samples drawn from a highly variable source population will tend to contain relatively large amounts of variability, while those drawn from a fairly homogeneous population will tend to contain smaller amounts of variability. Moreover, the larger the size of the sample, the closer the reflection will tend to be.
You will recall from Chapter 2 that the raw measure of variability within a set of numerical values—X1, X2, X3, etc.—is the sum of squared deviates, SS, for which the formulas are
The variance of the set of Xi values is then the average of these squared deviates:
and the standard deviation is the square root of that average:
The following demonstration focuses on the variance. Each time you click one of the buttons below, your computer will reach into our current source population and draw 10 random samples of the indicated size, either N=5 or N=20. It will also calculate and display the variance of each sample along with the average variance of the whole set of 10 samples and the cumulative average variance of all the samples that you draw through repeated clicking. Please click each of the buttons for as many times as you can muster the patience, noting in particular the values that appear toward the bottom of each text box under the heading of "cumulative average variance." If you click each button 30 or 40 times, so as to accumulate 300 to 400 samples of each size, you will almost certainly find that the cumulative average variance for samples of size N=20 will be larger than for samples of size N=5. (I say "almost certainly" because, whenever you are drawing samples at random, there is always the slight chance of ending up with something extraordinary. If this should happen in your case, click the "Clear" buttons and start over.)
If you really want to get a hands-on idea of what is going on here, keep clicking the two buttons again and again, non-stop over the next several weeks, so as to accumulate a vast number of samples of each size. I do not imagine anyone will actually do this. But if you were to do it, here is what you would find. For your zillion random samples of size N=5, the cumulative average sample variance would very closely approximate the value of 6.0; and for your zillion random samples of size N=20, it would very closely approximate the value of 7.125.
There are two reasons why I am able to make this claim. The first is merely adventitious, occasioned by the fact that I needed to construct a specific source population in order to illustrate these principles. As the designer of this population I happen to know, and will now share the fact with you, that its variance is exactly
: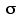 2source = 7.5 [hence:source = ±2.74]
2source = 7.5 [hence:source = ±2.74]
The second reason is one of principle and obtains irrespective of whether you know the variability of the source population in advance. When drawing random samples of size N from a normally distributed source population, the average variance of those samples will end up in the long haul being equal to a certain proportion of the variance of the population. That proportion is determined by the size of the samples; its precise value is given by the ratio(N—1)/N. For samples of size N=5 the proportion is 4/5=0.80, so here we would expect the average sample variance to end up as 0.80x7.5=6.0. For samples of size N=20 it is 19/20=0.95, so we would expect 0.95x7.5=7.125. And so on. For all cases where samples of size N are randomly drawn from a normally distributed source population, the form of the relationship is
Conversely, the variance of the source population would be equal to the average sample variance multiplied byN/(N—1):
It is this latter version of the relationship that permits us to estimate the variability of a source population—in those more realistic cases where we do not know it in advance—on the basis of a single sample. For even though the variability contained within individual samples might not fall precisely at the average, it will nonetheless tend to fall somewhere near the average. In effect, therefore, the observed variance of a single sample can be taken as an estimate of "mean sample variance"; and that, in turn, can lead us to an estimate of the variance of the source population. What we end up with, of course, is still only an estimate. It is not precise, it does not pretend to be precise, and that fact will eventually have to be taken into account. But more of this later. Our immediate concern is with how the estimate can be obtained, and what can be done with it once we have it.
The general precept is this: If a random sample of size N is drawn from a normally distributed source population, a useful estimate of the source population's variance(i2source) can be obtained through multiplying the observed variance of the sample (s2) by the ratio N/(N—1). Thus,
For practical computational purposes, this estimate can be reached in a somewhat more streamlined fashion. As we reminded ourselves just a moment ago, the variance of an observed set of Xi values is simply the average of the sum of squared deviates:
Multiply that average by N/(N—1) and you end up with
We will symbolize this modified version of a sample's variance as"{s2}" in order to distinguish it from the plain-vanilla version that we examined in Chapter 2; similarly, we will use "{s}" to denote the modified standard deviation that would result from taking the square root of {s2}. Thus, on the basis of any particular sample randomly drawn from a population that we can reasonably suppose to be normally distributed, the variance and standard deviation of the population can be estimated as
and
¶Estimating the Standard Deviation of the Sampling Distribution of Sample Means
We saw in Part 1 of this chapter that the variance of the sampling distribution of sample means is equal to the variance of the source population divided by N.
When:2source is unknown, as it usually is, the value of:2M can be estimated by substituting {s2}, which is the estimate of:2source obtained through the procedure described above. Thus
This in turn would allow you to estimate the standard deviation of the sampling distribution of sample means ("standard error of the mean") as
To give you an idea where this is headed, suppose you have reason to believe that a certain source population is normally distributed, but you have no precise knowledge of its central tendency or variability. On the basis of certain theoretical considerations, however, you do have reason to suspect that the mean of the population issource=50.0. To test this hypothesis, you draw a random sample of size N=25 from the population. Your reasoning for the test is straightforward: If the mean of the population is 50.0, then the mean of any particular sample randomly drawn from the population should fall somewhere in the vicinity of 50.0. So you draw your sample and find its mean to be MX=53.0, as compared with your hypothetical population mean of source=50.0.
Well, yes, 53.0 is "somewhere in the vicinity" of 50.0—although, depending on your scale of measurement, that could be a bit like saying that Glasgow is somewhere in the vicinity of London. The observed sample mean of 53.0 clearly differs from 50.0. The question is, does it differ significantly? That is: If the mean of the population truly were 50.0, how likely would it be, by mere chance coincidence, that the mean of a sample randomly drawn from the population would fall 3 or more points distant from 50.0?
If only you knew the variability of the source population, you could directly calculate:2M, the standard deviation of the relevant sampling distribution of sample means. And with that value in hand you could then plug your numbers into the appropriate version of the sample-mean z-ratios described in Part 1 of this chapter:
As it happens, you do not know the variability of the source population, hence cannot directly calculate either:2M or z. But as Moliere had his character Tartuffe say on one occasion: Though Heaven forbids certain gratifications, there are nonetheless "ways and means of accommodation." In the present case, the accommodation comes about by way of systematic estimates. Suppose that you observe within your sample a sum of squared deviates of SS=625. On this basis you could estimate the variance of the population as
And that in turn would allow you to estimate ('est.") the standard deviation of the sampling distribution as
The next step will be obvious. With your estimated value of:M in hand, you can now go on to calculate what is essentially an estimate of the z-ratio examined a moment ago. To make it clear that what we are now calculating is grounded on several layers of estimation, the convention is to label it with the letter t rather than z.
We will see a bit later that this distinction between t and z is not simply a matter of nomenclature.
¶Estimating the Standard Deviation of the Sampling Distribution of Sample-Mean Differences
There is a certain species of small furry animal known as the golliwump, of which half are green and the other half are blue. An investigator has framed the hypothesis that green golliwumps are on average smarter than blue golliwumps. To test this hypothesis he draws one random sample of Na=20 greens and another of Nb=20 blues. He then administers a standard test of golliwump intelligence to each of the individual subjects in the two samples, finding that the mean score of the greens isMXa=105.6, while that of the blues is only MXb=101.3.
Here again is one of those "if only" scenarios. If only our investigator knew the variability of test scores within the entire population of golliwumps, he would be able to calculate directly the standard deviation of the relevant sampling distribution,
which would in turn permit the calculation of the two-samplez-ratio described in Part 1:
The logic of estimation in this case is analogous to what we examined above for the one-sample situation. Suppose that the values for sum of squared deviates within the two samples wereSSa=4321 and SSb=4563. If you were to estimate the variance of the source population on the basis of sample A separately, it would be
Estimated on the basis of sample B separately, it would be
Blending these two separate variance estimates together in just the right way will give you a composite estimate known as the pooled variance. (Note the subscript "p" to indicate "pooled.")
Returning now to the formula for the direct calculation of the standard deviation of the sampling distribution,
we substitute {s2p} forisource and end up with
The next step is then to calculate at-ratio on analogy with the two-sample z-ratio described above:
In effect, we are estimating that the true value of the sampling distribution's standard deviation is somewhere in the vicinity of±4.84, and accordingly that the true value of z is somewhere in the vicinity of +0.89.
So here it stands, estimate piled on estimate, and the whole structure hedged in with an escape clause that reads "somewhere in the vicinity." At first glance you might think it hardly possible to squeeze from these rather spongy estimates anything even remotely resembling a precise probability assessment. Indeed, were it not for the work of the statistician W.S. Gosset (who wrote under the pseudonym of "Student"), we might have to conclude at this point that the first-hand impression is accurate. In the final portion of this chapter you will catch your first glimpse of the extraordinarily useful inferential tool that Gosset's work created.
¶Estimating the Mean of a Normally Distributed Source Population
In Part 1 we noted that a random sample will tend to reflect the properties of the population from which it is drawn. Among these reflected properties is the population's central tendency. So here is the simple, straightforward way of estimating the mean of our current source population. Draw from it a random sample of size N, and then let the mean of that sample serve as your estimate of the mean of the population.
The principle underlying such a process is that the mean of any particular sample can be taken as an unbiased estimate of the mean of the population from which the sample is drawn. In general, a biased estimate is one that will systematically underestimate the true value, or systematically overestimate it, while an unbiased estimate is one that avoids this tendency. The unbiased estimate might prove to be either under or over the true value in particular cases, but it will not move in either of these directions systematically. It is roughly analogous to shooting arrows at a target. The archer who tends to hit below the bull's eye is systematically biased in one direction, while the archer who tends to hit above it is systematically biased in the other. An archer without such a systematic bias will hit below and above the bull's eye in equal measure, and occasionally she will even hit it dead center.
But of course, even an unbiased archer is not necessarily a contender for the world title. The shots of one might tend to cluster within two or three inches of dead center, while those of another might scatter out over a distance of two or three feet. Similarly, some sample means can be regarded as very close estimates of the population mean, while others can be taken only as loose ballpark estimates.
In the following table is a button labeled "Sample." Each time you click it, you computer will draw a random sample of whatever size is indicated in the cell labeled "sample size." The default value of "sample size" is 5, though you can reset it to any positive integer value you might wish. I suggest you begin by drawing a few samples of size N=5, then a few of size N=10, and so on until you have worked your way up to some fairly large sample sizes. By the time you are drawing samples of size N=100, you will begin to get a pretty close fix on the mean of the source population. With samples of larger sizes, it will be closer still. (Note, however, that large sample sizes will take longer to run, especially if your browser is Internet Explorer. ) To help you avoid getting lost in the fractional numerical details of your samples, each sample mean is also shown rounded to the nearest integer value.
So, click, click, click away. And then, when you have finished, click here to continue with the text of this chapter.
If you have taken the time to perform the above exercise, you have almost certainly arrived at the conclusion that the mean of our current source population is somewhere in the vicinity of 15. Perhaps a shade more than 15, perhaps a shade less, but in any event somewhere in that vicinity.
Just how narrowly or broadly you can set the boundaries of "vicinity" depends on the size of the sample. The fact that the mean of our current source population lies somewhere in the neighborhood of 15 might not have been very obvious when you were drawing small samples, but it must surely have become so as the sizes of your samples increased. In general, a larger sample sets the boundaries of "vicinity" more narrowly, while a smaller sample sets them more broadly. From what we observed in Part 1 concerning the sampling distribution of sample means, you will know that these boundaries are also determined by the amount of variability that exists within the population from which the sample is drawn. A relatively small amount of variability within the source population would define "vicinity" fairly narrowly, while a relatively large amount would define it fairly broadly. Either way, the general structure of this process of estimation is
In Chapter 10 we will show precisely how you go about defining the boundaries of "vicinity." Meanwhile, so as not to keep you in suspense, I will tell you that your estimate of "somewhere in the vicinity of 15" is right on target. The mean of the source population from which you were drawing your samples is precisely
¶Estimating the Variability of a Normally Distributed Source Population
The principle here is akin to the one just discussed in connection with the central tendencies of samples and populations, though with one very important difference. The variability that is observed to exist within a sample can be taken as an estimate of the variability of the population, but not as an unbiased estimate. In general, the variability that appears within samples will tend to be smaller than the variability that exists within the entire population. In a relatively small percentage of cases it will be larger, and occasionally it might even hit the variability of the population dead center; but overall there is a strong bias in favor of the observed variability of a sample coming out as an underestimate of the variability of the population.
Here as well, the basic concept is that a random sample will tend to reflect the properties of the population from which it is drawn. Samples drawn from a highly variable source population will tend to contain relatively large amounts of variability, while those drawn from a fairly homogeneous population will tend to contain smaller amounts of variability. Moreover, the larger the size of the sample, the closer the reflection will tend to be.
You will recall from Chapter 2 that the raw measure of variability within a set of numerical values—X1, X2, X3, etc.—is the sum of squared deviates, SS, for which the formulas are
| conceptual: SS = ∑(Xi — MX)2 |
| computational: SS = | ∑Xi2 — | (∑Xi)2 2N2 | From Ch. 2, Pt. 2. |
The variance of the set of Xi values is then the average of these squared deviates:
| variance = | SS N |
and the standard deviation is the square root of that average:
| standard deviation = | sqrt | [ | SS N | ] | From Ch. 2, Pt. 2. |
The following demonstration focuses on the variance. Each time you click one of the buttons below, your computer will reach into our current source population and draw 10 random samples of the indicated size, either N=5 or N=20. It will also calculate and display the variance of each sample along with the average variance of the whole set of 10 samples and the cumulative average variance of all the samples that you draw through repeated clicking. Please click each of the buttons for as many times as you can muster the patience, noting in particular the values that appear toward the bottom of each text box under the heading of "cumulative average variance." If you click each button 30 or 40 times, so as to accumulate 300 to 400 samples of each size, you will almost certainly find that the cumulative average variance for samples of size N=20 will be larger than for samples of size N=5. (I say "almost certainly" because, whenever you are drawing samples at random, there is always the slight chance of ending up with something extraordinary. If this should happen in your case, click the "Clear" buttons and start over.)
If you really want to get a hands-on idea of what is going on here, keep clicking the two buttons again and again, non-stop over the next several weeks, so as to accumulate a vast number of samples of each size. I do not imagine anyone will actually do this. But if you were to do it, here is what you would find. For your zillion random samples of size N=5, the cumulative average sample variance would very closely approximate the value of 6.0; and for your zillion random samples of size N=20, it would very closely approximate the value of 7.125.
There are two reasons why I am able to make this claim. The first is merely adventitious, occasioned by the fact that I needed to construct a specific source population in order to illustrate these principles. As the designer of this population I happen to know, and will now share the fact with you, that its variance is exactly
The second reason is one of principle and obtains irrespective of whether you know the variability of the source population in advance. When drawing random samples of size N from a normally distributed source population, the average variance of those samples will end up in the long haul being equal to a certain proportion of the variance of the population. That proportion is determined by the size of the samples; its precise value is given by the ratio
| mean sample variance =: | N—1 N |
Conversely, the variance of the source population would be equal to the average sample variance multiplied by
| :: | N N—1 |
It is this latter version of the relationship that permits us to estimate the variability of a source population—in those more realistic cases where we do not know it in advance—on the basis of a single sample. For even though the variability contained within individual samples might not fall precisely at the average, it will nonetheless tend to fall somewhere near the average. In effect, therefore, the observed variance of a single sample can be taken as an estimate of "mean sample variance"; and that, in turn, can lead us to an estimate of the variance of the source population. What we end up with, of course, is still only an estimate. It is not precise, it does not pretend to be precise, and that fact will eventually have to be taken into account. But more of this later. Our immediate concern is with how the estimate can be obtained, and what can be done with it once we have it.
The general precept is this: If a random sample of size N is drawn from a normally distributed source population, a useful estimate of the source population's variance
| estimated: | N N—1 |
For practical computational purposes, this estimate can be reached in a somewhat more streamlined fashion. As we reminded ourselves just a moment ago, the variance of an observed set of Xi values is simply the average of the sum of squared deviates:
| s2 = | SS N |
Multiply that average by N/(N—1) and you end up with
| SS N | x | N N—1 | = | SS N—1 |
We will symbolize this modified version of a sample's variance as
| {s2} = | SS N—1 | [= estimate of: |
and
| {s} = sqrt | [ | SS N—1 | ] | [= estimate of: |
¶Estimating the Standard Deviation of the Sampling Distribution of Sample Means
We saw in Part 1 of this chapter that the variance of the sampling distribution of sample means is equal to the variance of the source population divided by N.
| : | : N | From Ch. 9, Pt. 1. |
When:
| estimated: | {s2} N | Recall that {s2} = SS/(N—1) |
This in turn would allow you to estimate the standard deviation of the sampling distribution of sample means ("standard error of the mean") as
| estimated: | sqrt | [ | {s2} N | ] |
To give you an idea where this is headed, suppose you have reason to believe that a certain source population is normally distributed, but you have no precise knowledge of its central tendency or variability. On the basis of certain theoretical considerations, however, you do have reason to suspect that the mean of the population is
Well, yes, 53.0 is "somewhere in the vicinity" of 50.0—although, depending on your scale of measurement, that could be a bit like saying that Glasgow is somewhere in the vicinity of London. The observed sample mean of 53.0 clearly differs from 50.0. The question is, does it differ significantly? That is: If the mean of the population truly were 50.0, how likely would it be, by mere chance coincidence, that the mean of a sample randomly drawn from the population would fall 3 or more points distant from 50.0?
If only you knew the variability of the source population, you could directly calculate
| z = | MX— : | = | 53—50 : | From Ch. 9, Pt. 1. |
As it happens, you do not know the variability of the source population, hence cannot directly calculate either
| {s2} = | SS N—1 | = | 625 24 | = 26.04 |
And that in turn would allow you to estimate ('est.") the standard deviation of the sampling distribution as
| est.: | = sqrt | [ | {s2} N | ]
|
|
| = sqrt | [
| 26.04 | 25 ]
| = ±1.02
| |
The next step will be obvious. With your estimated value of
| t | = | MX— est.:
|
| = | 53—50 | 1.02 = +2.94 | |
We will see a bit later that this distinction between t and z is not simply a matter of nomenclature.
¶Estimating the Standard Deviation of the Sampling Distribution of Sample-Mean Differences
There is a certain species of small furry animal known as the golliwump, of which half are green and the other half are blue. An investigator has framed the hypothesis that green golliwumps are on average smarter than blue golliwumps. To test this hypothesis he draws one random sample of Na=20 greens and another of Nb=20 blues. He then administers a standard test of golliwump intelligence to each of the individual subjects in the two samples, finding that the mean score of the greens is
Here again is one of those "if only" scenarios. If only our investigator knew the variability of test scores within the entire population of golliwumps, he would be able to calculate directly the standard deviation of the relevant sampling distribution,
| i | [ | i Na | + | i Nb | ] | From Ch. 9, Pt. 1. |
which would in turn permit the calculation of the two-sample
| z = | MXa—MXb i | = | 105.6 — 101.3 i | From Ch. 9, Pt. 1. |
The logic of estimation in this case is analogous to what we examined above for the one-sample situation. Suppose that the values for sum of squared deviates within the two samples were
| {s2a} = | SSa Na—1 | = | 4321 19 | = 227.42 |
Estimated on the basis of sample B separately, it would be
| {s2b} = | SSb Nb—1 | = | 4563 19 | = 240.16 |
Blending these two separate variance estimates together in just the right way will give you a composite estimate known as the pooled variance. (Note the subscript "p" to indicate "pooled.")
| {s2p} | = | SSa+SSb (Na—1)+(Nb—1)
|
|
| =
| 4321+4563 | 19+19 = 233.79 | |
Returning now to the formula for the direct calculation of the standard deviation of the sampling distribution,
| i | [ | i Na | + | i Nb | ] | From Ch. 9, Pt. 1. |
we substitute {s2p} fori
| est.i | = sqrt | [ | {s2p} Na | + | {s2p} Nb | ]|
|
|
| = sqrt | [ | 233.79 | 20 + | 233.79 | 20 ] | = ±4.84 | |
The next step is then to calculate a
| t | = | MXa—MXb est.i
|
|
| = | 105.6 — 101.3 | 4.84 = +0.89 | |
In effect, we are estimating that the true value of the sampling distribution's standard deviation is somewhere in the vicinity of
So here it stands, estimate piled on estimate, and the whole structure hedged in with an escape clause that reads "somewhere in the vicinity." At first glance you might think it hardly possible to squeeze from these rather spongy estimates anything even remotely resembling a precise probability assessment. Indeed, were it not for the work of the statistician W.S. Gosset (who wrote under the pseudonym of "Student"), we might have to conclude at this point that the first-hand impression is accurate. In the final portion of this chapter you will catch your first glimpse of the extraordinarily useful inferential tool that Gosset's work created.
End of Chapter 9, Part 2.
Return to Top of Chapter 9, Part 2
Go to Chapter 9, Part 3
| Home | Click this link only if the present page does not appear in a frameset headed by the logo Concepts and Applications of Inferential Statistics |